MDP
_不确定世界的决策方法/1.png)
马可夫决策过程( Markov Decision Processes):不确定世界的决策方法
今天来学习一下马可夫决策过程,以下简称MDP。 现在考虑一个问题,如上图所示,机器人前面有一堆火,而它需要去取火那边的钻石,它如何才能取到那颗钻石。 下面是一张俯视图:

Goal Directed Task
/2.png)
以图片为目标的视觉强化学习 -- 代码解析上篇(rlkit安装及部分代码及函数的解析和使用)
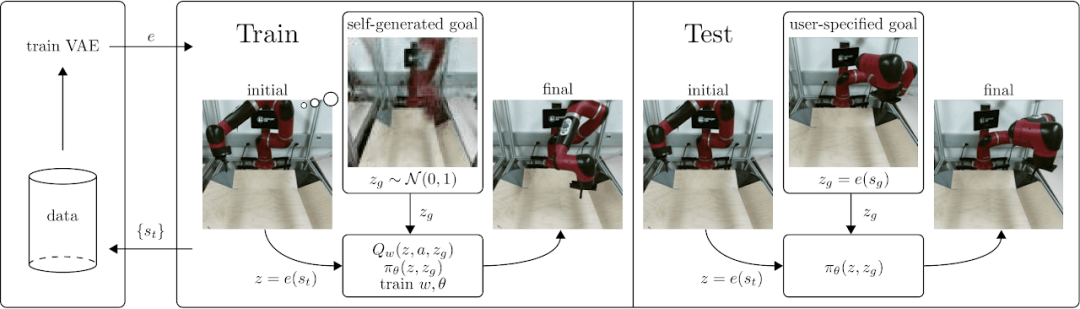
之前有讲过一篇论文,今天来讲讲它的代码: 论文解析的链接是:以图片为目标的视觉强化学习 这篇研究以及这篇研究的后续研究,源代码都有公开,我们的目标是把这个库都解析一遍,感兴
以图片为目标的视觉强化学习
今天说一下发表于NIPS 2018的一篇文章,以图片为目标的视觉强化学习。 为了更直观的了解一下这篇论文解决的问题,可以看一下这个链接里的视频demo: https://sit
换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务——策略学习模型
上篇:换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务——因果归纳模型 系列第一篇:换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务(上)
换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务——因果归纳模型
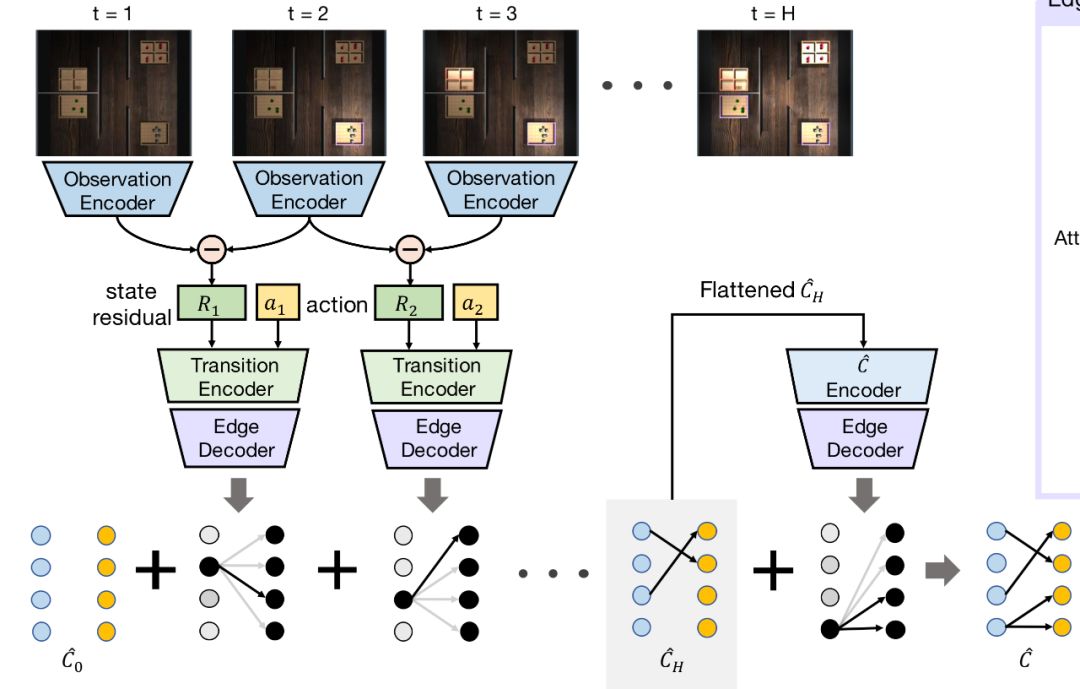
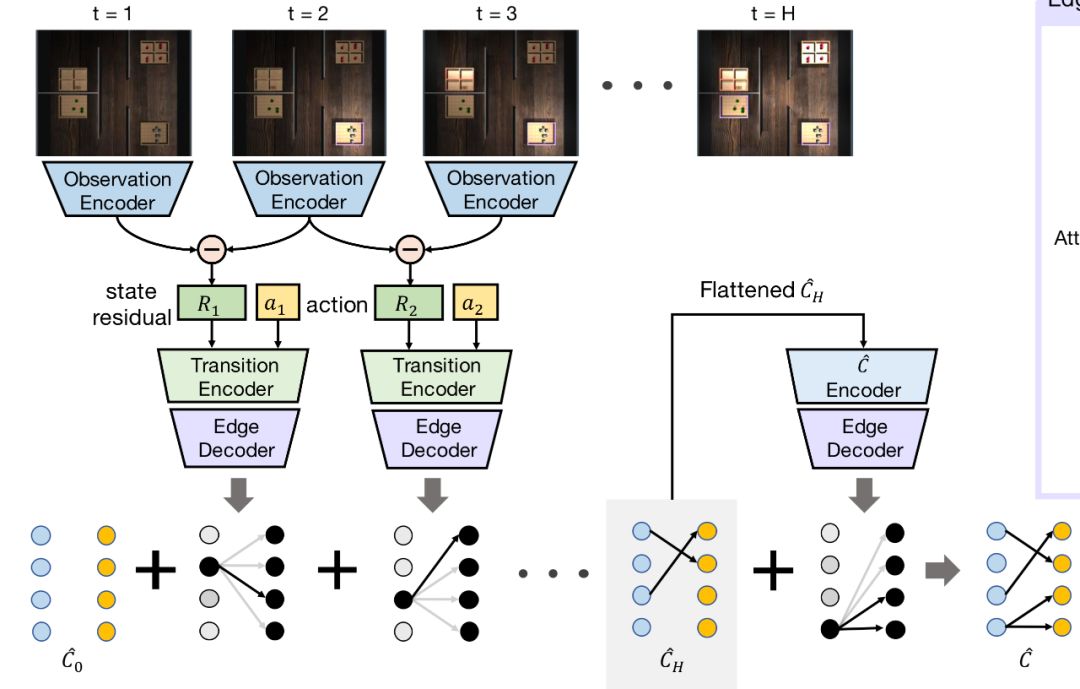
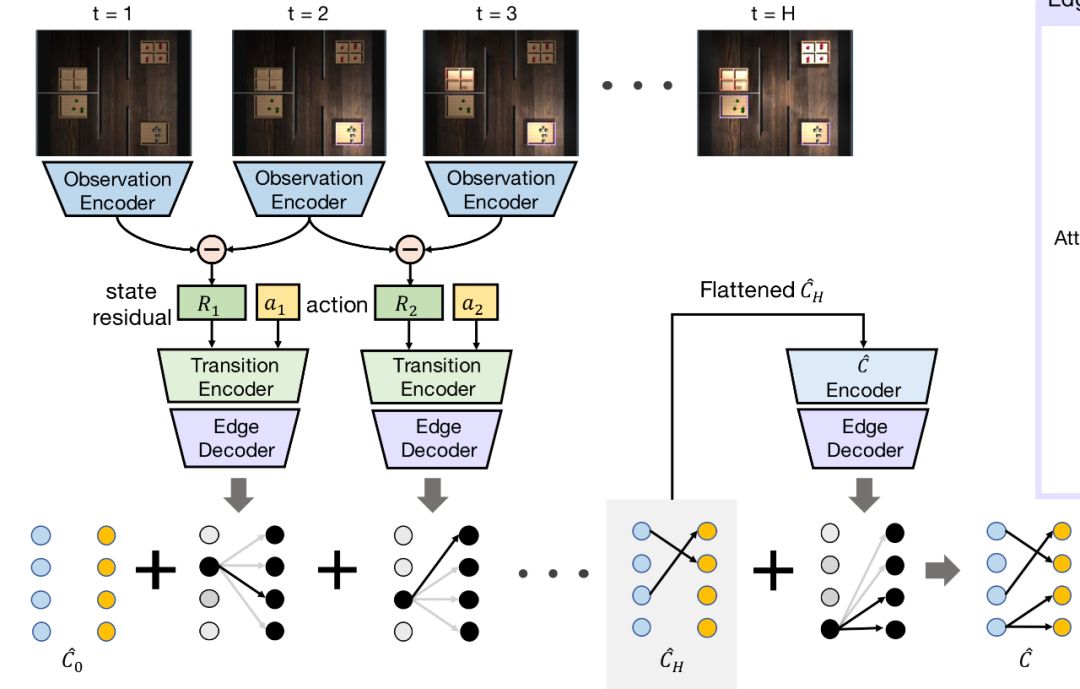
上篇:换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务——生成数据 上上篇:换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务(上) 今天我
换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务——生成数据
上篇:换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务(上) 今天我们来说一说《CAUSAL INDUCTION FROM VISUAL OBSERVATIONS
/3.png)
换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务(上)
能让机器拥有智慧的,可能既不是机器学习,也不是深度学习。 今天我们来说一说这篇文章: 什么是因果,《The Book of Why》中举了两个例子,公鸡打鸣
Causality

D-separation,d-connection
这篇介绍一个颇复杂的概念,d-separation,关于图和因果关系的一个小概念,逻辑有点绕。 关于这个概念的前因后果可以看这个链接:https://www.andrew.cmu.e
MIT Causality Course

MIT因果迷你课笔记 — 因果归纳和机器学习之Domain Adaptation
系列首篇:MIT因果迷你课笔记 —— 相关和因果 上篇:MIT因果迷你课笔记 — 因果归纳和机器学习之强化学习 这是这门课最后一部分的内容,因果归纳和机器学习。 总共分四个部分,
MIT因果迷你课笔记 — 因果归纳和机器学习之强化学习
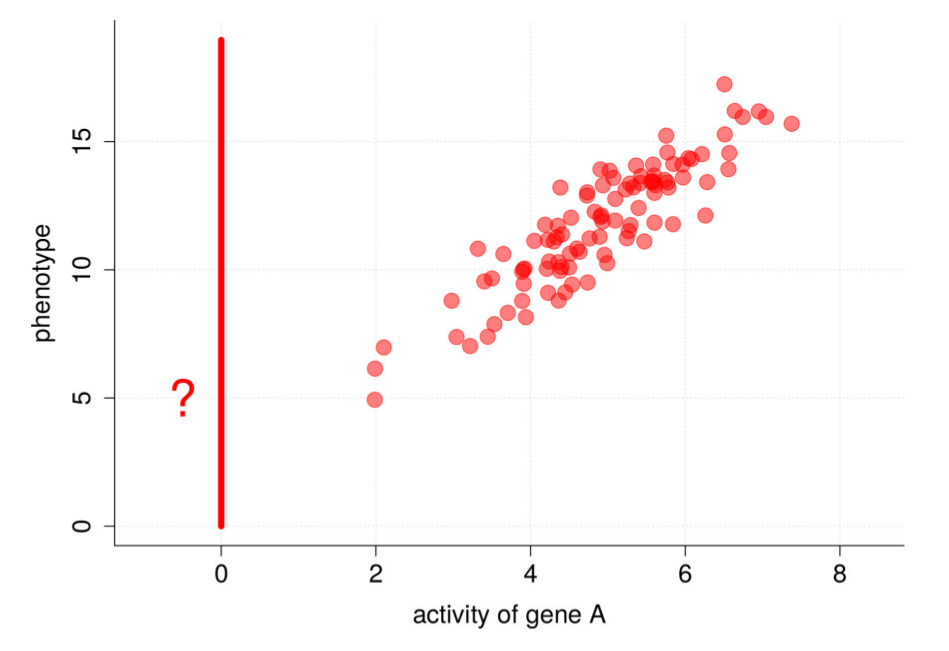
系列首篇:MIT因果迷你课笔记 —— 相关和因果 上篇:MIT因果迷你课笔记 — 因果归纳和机器学习之half-sibling regression 这是这门课最后一部分的内容,因果归纳和

MIT因果迷你课笔记 — 因果归纳和机器学习之half-sibling regression
系列首篇:MIT因果迷你课笔记 —— 相关和因果 上篇:MIT因果迷你课笔记 — 因果归纳和机器学习之半监督学习 这是这门课最后一部分的内容,因果归纳和机器学习。 总共分四个部分
MIT因果迷你课笔记 — 因果归纳和机器学习之半监督学习
系列首篇:MIT因果迷你课笔记 —— 相关和因果 上篇:MIT因果迷你课笔记 —— 基于不变性的因果预测(invariant causal prediction) 这是这门课最后一部分的内
/1.png)
MIT因果迷你课笔记 —— 基于不变性的因果预测(invariant causal prediction)
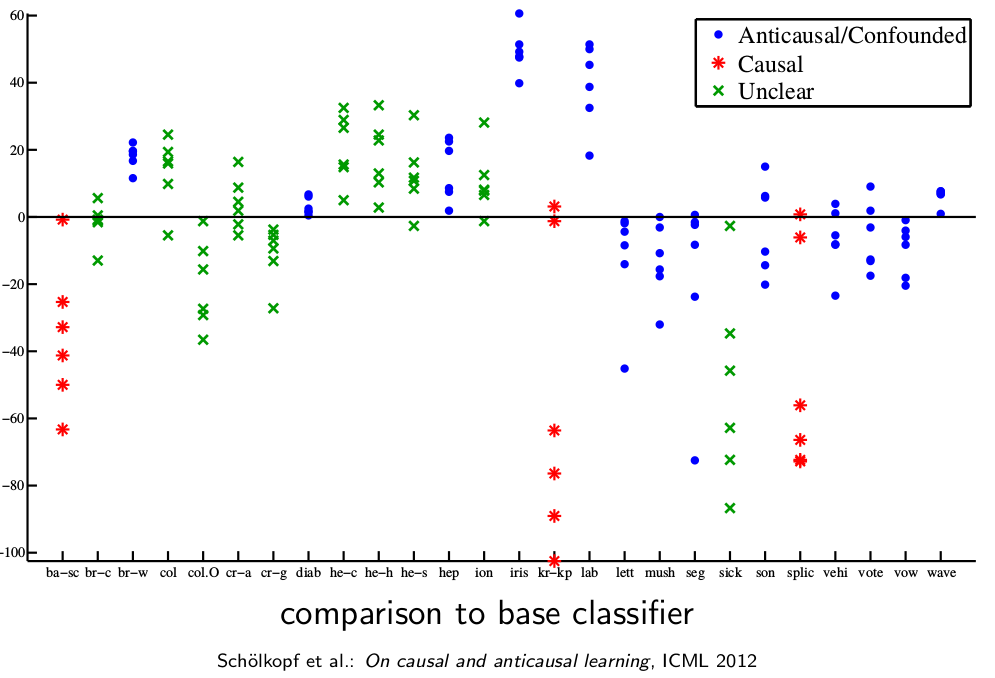
系列首篇:MIT因果迷你课笔记 —— 相关和因果 上篇:MIT因果迷你课笔记 —— 因果归纳模型的评估方式(SHD和SID) 这篇是发现因果关系的最后一篇,也是这里要提的最后一个发现因果关
/2.png)
MIT因果迷你课笔记 —— 因果归纳模型的评估方式(SHD和SID)
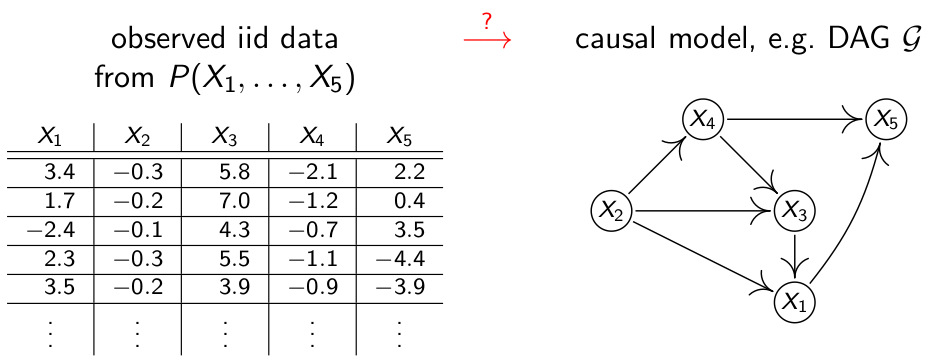
系列首篇:MIT因果迷你课笔记 —— 相关和因果 上篇:MIT因果迷你课笔记 —— 发现因果关系3(多变量) 如何评估因果模型? 如何评估你的因果归纳模型?这个问题转换一下可以是如
/3.png)
MIT因果迷你课笔记 —— 发现因果关系3(多变量)
系列首篇:MIT因果迷你课笔记 —— 相关和因果 上篇:MIT因果迷你课笔记 —— 发现因果关系2(restricted structural causal model) 这节继续讲 restri
/2.png)
MIT因果迷你课笔记 —— 发现因果关系2(restricted structural causal model)
系列首篇:MIT因果迷你课笔记 —— 相关和因果 上篇:MIT因果迷你课笔记 —— 发现因果关系1 上篇中,我们提到了一些方法和假设,可以从数据分布中解析出因果关系,比如Causal Ma
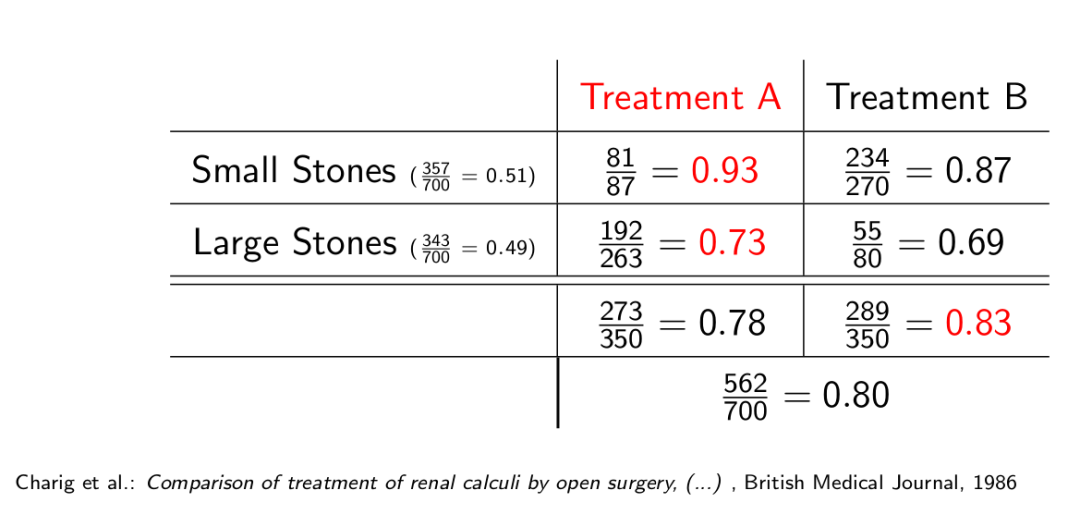
MIT因果迷你课笔记 —— 发现因果关系1
上上篇:MIT因果迷你课笔记 —— 相关和因果 上篇:MIT因果迷你课笔记 —— 因果语言和因果推理 在这门课中,因果模型的形成主要包含因果关系的学习和发现(causal learning

MIT因果迷你课笔记 —— 因果语言和因果推理
一、分布和因果图 例1. 海拔和温度 假设,海拔和温度的分布及因果关系是已知的,且如下图所示: 海拔和温度存在因果关系,平均每上升100米,温度下降0.6摄氏度。上图
Loss Function
的设计/28.png)
ArcFace,CosFace,SphereFace,三种人脸识别算法的损失函数(Loss Function)的设计
最近看了点人脸识别算法,发现ArcFace,CosFace,SphereFace的损失函数(Loss Function)设计得非常有意思,且设计理念都是相似的,因此今天就记一篇损失函数的设计。
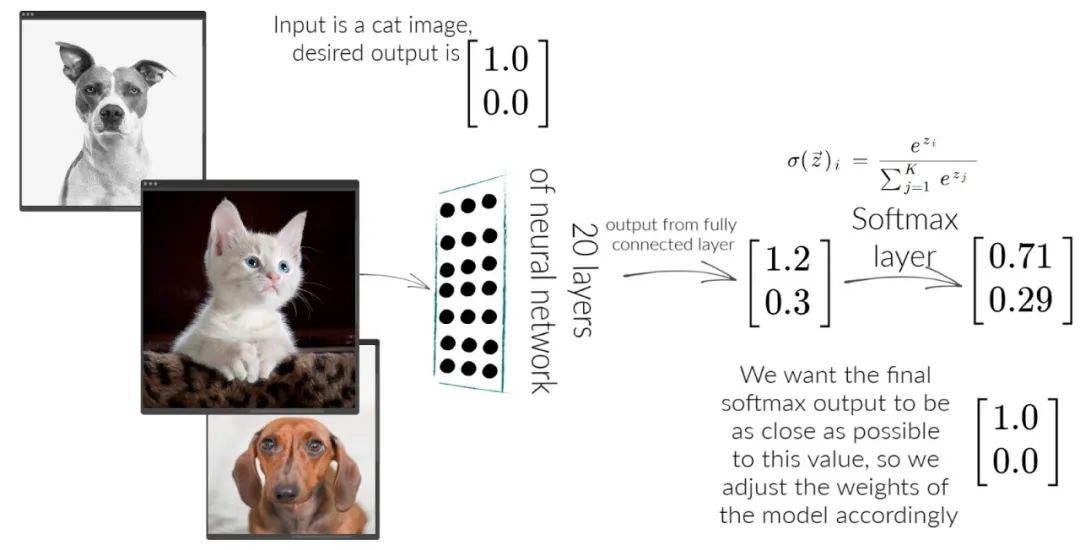
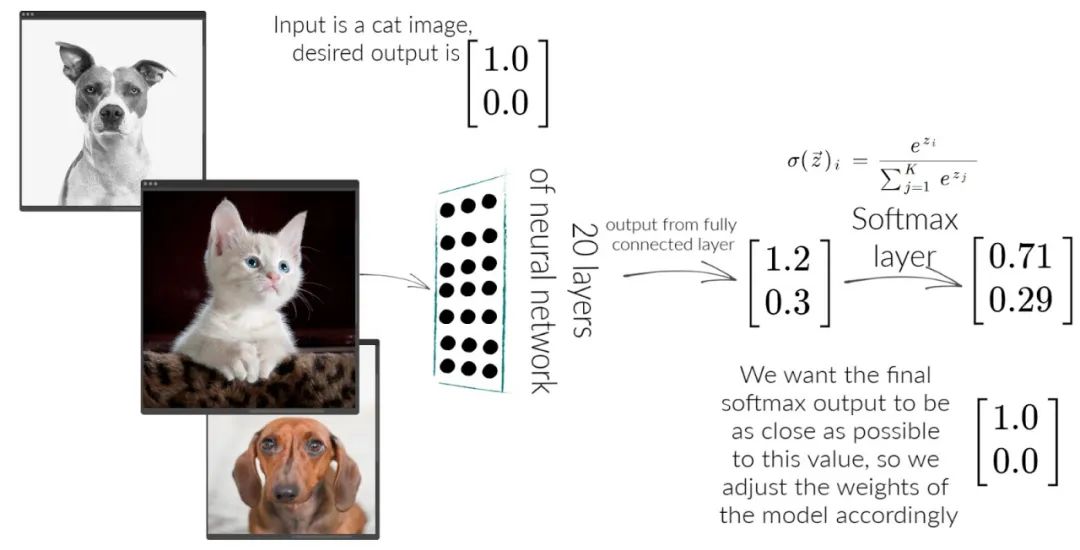
Cross Entropy Loss
交叉熵度量的是两个概率分布的差异。 要理解交叉熵,有很多小概念需要理解。 信息量,一个事件发生的概率越大,事件发生携带的信息量越小,发生的概率越小,事件发生携带的信息量越大
Stock
/1.jpeg)
美股资料收集(Python)
声明: 这篇笔记和参考均不构成任何投资建议哦。 本来这应该是一篇读书笔记,要翻译整理课程‘Nick McCullum, Algorithmic Trading Using Pyth
![Kaggle比赛系列:[Two Sigma] Using News to Predict Stock Movements](/assets/images/Kaggle比赛系列:[Two Sigma] Using News to Predict Stock Movements/2.png)
Kaggle比赛系列:[Two Sigma] Using News to Predict Stock Movements
不想学习的时候,不如想想怎么发财 这是一个和实现财富自由很接近的Kaggle比赛,通过新闻预测股价。 发起的公司叫Two Sigma,看公司图标: 这个名字,
Face Recognition
ArcFace,CosFace,SphereFace,三种人脸识别算法的损失函数(Loss Function)的设计
最近看了点人脸识别算法,发现ArcFace,CosFace,SphereFace的损失函数(Loss Function)设计得非常有意思,且设计理念都是相似的,因此今天就记一篇损失函数的设计。
Math

Kaggle比赛系列:Conway's Reverse Game of Life 2020
Conway是一位数学家,John Horton Conway,活跃于有限群论,结论,数论,组合博弈论和编码论。 他还为休闲数学的许多分支做出了贡献,最著名的是1970年,细胞自动机(cel
Game
Kaggle比赛系列:Conway's Reverse Game of Life 2020
Conway是一位数学家,John Horton Conway,活跃于有限群论,结论,数论,组合博弈论和编码论。 他还为休闲数学的许多分支做出了贡献,最著名的是1970年,细胞自动机(cel
Graph Network

关系归纳偏置,深度学习,和图网络
开个新坑。 DeepMind,Google Brain,MIT,University of Edinburgh,这阵容,不能不看。 这篇略有些不同,讨论的不是一个方法,
UC Berkeley CS294-158
/1.png)
UC Berkeley非监督学习--Implicit Models -- GANs (上)
翻译整理一下UC Berkeley非监督学习的课程。这篇翻译第五六讲Implicit Models – GANs。分三篇:上,中,下。 这个课程总共十二讲,官方链接: http
/1.png)
UC Berkeley非监督学习--Latent Variable Models -- VAE(潜变量模型--VAE)
翻译整理一下UC Berkeley非监督学习的课程。这篇翻译第四讲Latent Variable Models – VAE。 这个课程总共十二讲,官方链接: https://s
/1.png)
UC Berkeley非监督学习--流模型(Flow Models)
翻译整理一下UC Berkeley非监督学习的课程。这篇翻译第三讲Flow Models,流模型。 这个课程总共十二讲,官方链接: https://sites.google.c

UC Berkeley非监督学习--自回归模型
想系统学习一下生成网络,开个新坑,翻译整理一下UC Berkeley非监督学习的课程。这篇翻译第二讲Autoregressive Models,自回归模型。 这个课程总共十二讲,

UC Berkeley非监督学习--介绍
想系统学习一下生成网络,开个新坑,翻译整理一下UC Berkeley非监督学习的课程。 这个课程总共十二讲,官方链接: https://sites.google.com/vie
/3.png)
自监督学习(Self Supervised Learning)
今天来说一说自监督学习,根据Yann LeCun的报告,这是一类可以预测未来,回溯过去,补缺查漏的算法,是不是很有吸引力。 首先我们来了解一下这位科学家 Yann LeCun,看人先
Writing
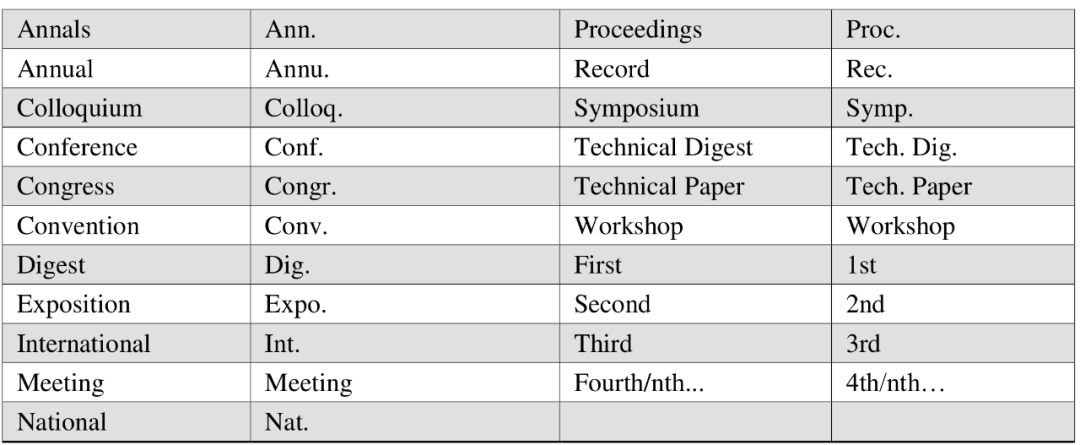
论文写作之Reference整理规范
咱写论文,每次都要整个Reference,每个期刊会议,规矩都会稍稍不一样,好在他们都会发指引文档。 这里就整理点基本的规范,统一的规则。每次可以照着找找自己的茬。这里不讲bib,l
ViT
 解析/2.png)
Facebook DeiT(Data-efficient Image Transformers) 解析
今天看Facebook AI的DeiT。比起Moco v3训练出来的模型,DeiT胜在模型小,训练和推理都更加迅速。且精准度还有了很大提高。 迅速到什么程度呢?用一个8-GPU服
的训练经验(Moco v3) -- Moco中的ViT/1.png)
Facebook自监督学习Visual Transformers(ViT)的训练经验(Moco v3) -- Moco中的ViT
系列首篇:自监督学习Visual Transformers(ViT)的训练经验(Moco v3) – 论文解析 系列上篇:Facebook自监督学习Visual Transforme
原理及代码解析/1.png)
ViT (Vision Transformer)原理及代码解析
今天我们来详细了解一下Vision Transformer。基于timm的代码。 1. Patch Embedding Transformer原本是用来做NLP的工作的,所以ViT的首
的训练经验(Moco v3) -- 训练代码解析/3.png)
Facebook自监督学习Visual Transformers(ViT)的训练经验(Moco v3) -- 训练代码解析
我们来讲Moco v3的代码。 论文的主要内容,参考系列首篇:自监督学习Visual Transformers(ViT)的训练经验(Moco v3) – 论文解析 官方
的训练经验(Moco v3) -- 论文解析/6.png)
自监督学习Visual Transformers(ViT)的训练经验(Moco v3) -- 论文解析
之前讲过一篇自监督学习:自监督学习(Self Supervised Learning),里面有提到几种把图像转成通用的embedding的方式,有CPC, SimCLR, 还有Moco。今天来
Stanford CS224N
/2.png)
Stanford CS224N笔记:词向量和词义(Word Vectors and Word Senses)
想系统学一下NLP,所以再开个新坑,如果有天我累死了,一定不要奇怪,都是自找的 一不小心写得小作文了,文章里不会所有概念都仔细说,但尽量会给参考链接,会对视频课程做一些延申。
GiantMIDI-Piano

钢琴曲转谱(Solo Piano Transcription)
今天来看一篇钢琴琴谱翻译的文章,出自ByteDance字节跳动,Giant-Piano(GiantMIDI-Piano:字节跳动发布的大型古典钢琴乐MIDI数据集)采用的转谱模型就是这个:

GiantMIDI-Piano:字节跳动发布的大型古典钢琴乐MIDI数据集
机器学习或深度学习的研究常常会用到一些公开数据集,这里呢,为大家介绍一个公开的古典钢琴乐的MIDI数据集。 这是字节跳动(ByteDance)的项目,项目地址: https:/
Distillation
Facebook DeiT(Data-efficient Image Transformers) 解析
今天看Facebook AI的DeiT。比起Moco v3训练出来的模型,DeiT胜在模型小,训练和推理都更加迅速。且精准度还有了很大提高。 迅速到什么程度呢?用一个8-GPU服
Crawler
上篇/0.png)
如何抓取一个微信公众号的所有文章(Python)下篇
声明:基本步骤和核心方法均参考[1],[2],细节有大不同,这篇着重于如何将抓取到的文章用markdown的格式保存下来。 1. 上篇中已经抓到了公众号的所有文章的题目和链接,下篇直接读入: im
如何抓取一个微信公众号的所有文章(Python)上篇
声明:基本步骤和核心方法均参考[1],未做诸多更改,但是细节上可能因为微信自己做了更新,爬取细节很不同,另外就是加入了一些文本处理的操作。 1. 注册微信公众号 -> 新建图文消息 ->