
想系统学习一下生成网络,开个新坑,翻译整理一下UC Berkeley非监督学习的课程。

这个课程总共十二讲,官方链接:
https://sites.google.com/view/berkeley-cs294-158-sp20/home
之前为了搞明白自监督学习的概念,整理过Lecture 7:自监督学习(Self Supervised Learning),这次没有意外的话至少会整理Lecture 1-6。
这篇整理这个课程的Lecture 1:Introduction。课程的介绍。
那什么是非监督学习(Unsupervised Learning):

非监督学习,用没有标签的数据训练深度神经网络,学习特征,主要分两类,一类是生成网络,像GAN,VAE这些,一类是自监督学习,label是机器自己产生的,不是人工标注的。
那么为什么要用非监督学习呢?

说到底,还是因为监督学习,效率太低。上图是Hinton的思考,Hinton也有一门神经网络课程,他喜欢通过对人脑运行机制的思考来探索人工智能的解决方案,会通过理解人脑的运行机制和特质来思考智能的来源,人大概活10^9秒,但是我们有大约10^14个神经触突。那么特别明显,如果我们是通过与世界的互动来获得标签,训练大脑,那么我们应该来不及聪明就死去了。所以人类获得智能的主要方式可能不是监督学习,而是非监督学习。
这里插一些题外话,关于Hinton,Hinton最初关于神经网络的灵感来源于高中时候获知的一些生物学上对大脑的研究结果,感兴趣的可以找Hinton的课程或者演讲看一看,比起枯燥的算法,这些算法的灵感来源,科学家们的思维方式,如何觉察,如何获得的灵感和毕生的执着和方向。这些可能是更值得学习的“算法”。
另外一位科学家也有相同的想法:
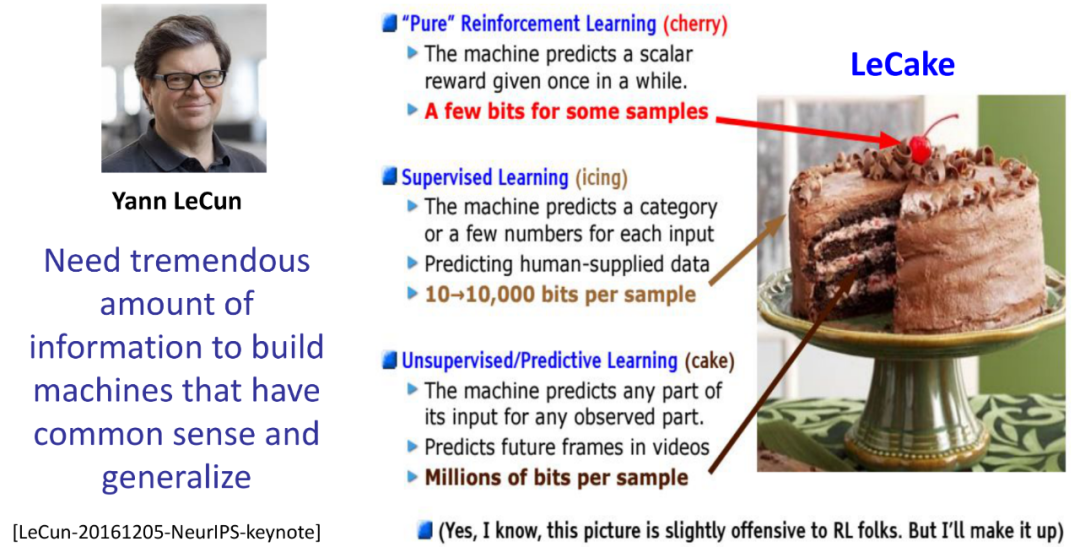
如果把深度学习领域比喻成一块蛋糕,那么LeCun认为,强化学习只是蛋糕上的樱桃,监督学习是蛋糕里的冰,而非监督学习才是蛋糕本身。

也有人从不同的角度来思考这个问题,比如思考理想化的智能是什么,就是压缩,即输入信息后,要能够提取所有特征,提取特征即产生一个简短的表达或描述,那么这个过程本质上就是对信息的压缩。根据奥卡姆剃刀原理,使用越少假设的理论越有可能是对的,延伸到深度学习,Solomonoff 的归纳推理理论是一个数学证明,即如果一个宇宙是由算法生成的,对该宇宙的观察,编码为一个数据集,最好由该数据集的最小可执行档案来预测,通俗来说就是程序越短,越有可能是适用的。AIXI是一个通用人工智能的数学理论形式,结合了Solomonoff Induction和顺序决策理论,是一个强化学习代理,最大化从环境中获得的期望总回报。AIXI同时考虑了所有可计算的假设(或环境),每一步,会用每个程序计算下一步动作和评估奖励,承诺奖励会根据该程序构成真实环境的主观信念进行加权。这种信念是根据程序的长度计算得出的,根据Solomonoff Induction,越长的程序越不可能是构成真实环境的程序。AIXI会在所有这些程序的加权和中选择具有最高期望总奖励的动作来执行。
这几个概念感兴趣的可以自己再梳理下,课程里只是一语带过了,没有仔细讲。
撇开理论上的,我们来看一看非监督学习的一些应用:

首先非监督学习可以产生新的数据,也可以根据一些输入来合成数据,比如输入一句话,产生一幅图,非监督学习可以用于信息压缩,训练得越好的模型压缩效果越好,压缩得到的特征向量可以用于下游任务的模型开发和训练,下游任务如果是监督学习,通常可以大大减少需要的人工标注量。另外,非监督学习中成功的模型架构也可以用于监督学习或者强化学习,或者给开发者以启发。
这里列一些非监督学习目前的成果(这些可以去看视频课程,因为没有什么难懂的点,另外有些示例是视频,这里没有上传):
1. 图像生成:

最早,可能是Hinton他们尝试用神经网络生成手写的数字。这个是2006年的事情了。

接下来VAE在2013年被提出来了,可以发现VAE产生的图片是模糊的,但是VAE比之后出来的GAN有自己的优点,这个之后说。

紧接着,2014年,GAN被发表,开始尝试生成人脸和风景,一开始效果并不好,但结果已经足够让人震撼。

GAN开始产生各式各样的变种,尝试去完成各种各样的任务,比如生成室内图。

更好的人脸生成,但很多生成的不是很好。

由低解析度的图片产生高解析度的图片,把模糊图片变清晰。

改造,把马变成斑马。

改变特征向量,产生不同的图。

清晰,高真人脸。
2. 语音生成
模型产生的语音和真实的人的语音是很难被区别开的。
3. 视频生成

4. 文本生成

Char-rnn是个非常优秀的文本生成模型,他不挑内容,公式也能生成,代码也能生成,英语可以,其他语言也可以,网络结构是基于LSTM,也非常简单。但这个模型现在被用得比较少了。现在大家的注意力都在Transformer上。基于Transformer,OpenAI开发了GPT-2,机器人可以产生有意义的文字,甚至可以说故事。

https://app.inferkit.com/demo
有空可以去上面的网址逗逗机器人。
5. 压缩
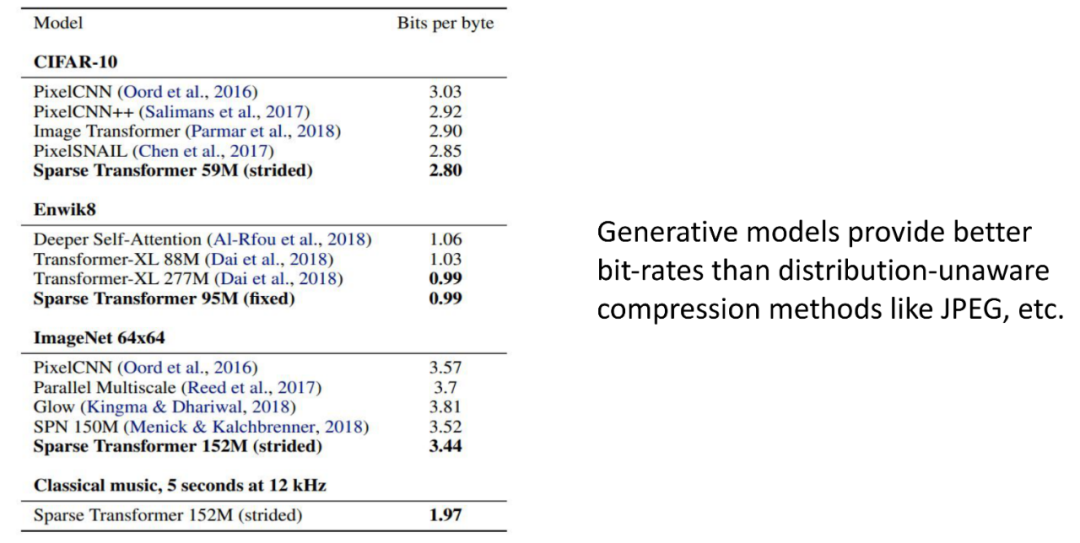
以上是无损压缩,压缩按是否有信息损失可以分为无损压缩和有损压缩,无损压缩时,没有信息会在压缩过程中损失,所以比较的是各个方法可以把文件压缩到多小,有损压缩在信息压缩的过程中会造成信息损失,但通常可以把文件压很小,但也因此信息质量会变差,因此会比较压缩到同样大小文件时,不同压缩方法压缩出来的文件品质如何,比较的是压缩后的信息质量。

这是有损压缩。有损压缩更受欢迎。
6. 下游任务 – 情感计算

比如上面这段话,不同的句子有不同的感情色彩,前几句,情感是正面的,后面几句情感则是负面的。下游任务是说,这个功能是用训练好的语义模型进行再训练或者从训练好的模型中挖掘有用信息等方式来完成的。
7. 下游任务 – 语义理解
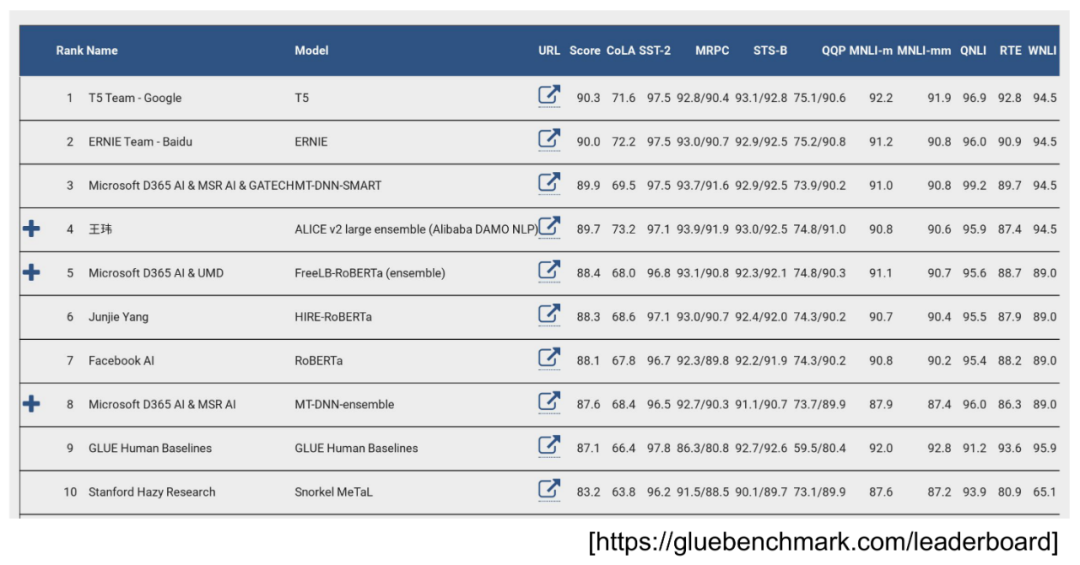
注意一下,9是Human Level,但这不是说现在机器的语义理解就已经强过人类了,只是在特定的数据集上或任务上如此表现。
8. 下游任务 – 图像识别
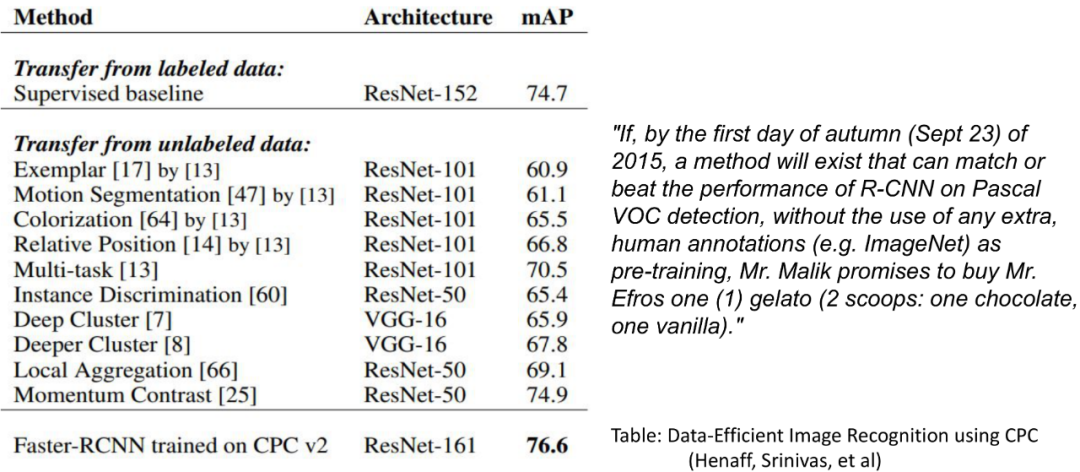
继语义之后,非监督学习在图像领域也获得了巨大成功。这个可以看自监督学习(Self Supervised Learning)。
最后老师总结了一下:

[1] Alex_Altair, An Intuitive Explanation of Solomonoff Induction, LessWrong, 2012
/1.png)
/1.png)
/1.png)
Comments