
上篇:换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务(上)
今天我们来说一说《CAUSAL INDUCTION FROM VISUAL OBSERVATIONS FOR GOAL DIRECTED TASKS》实验中生成数据的方式。
官方源代码地址:
https://github.com/StanfordVL/causal_induction
测试这个代码依赖一个软件:mujoco, mujoco-py, 安装可以参考这篇:
https://maple52046.github.io/2020/04/25/Mujoco-Installation/#
1. 生成数据(Generate Data)
python3 collectdata.py --horizon 7 --num 7 --fixed-goal 0 --structure one_to_one --seen 10 --images 1 --data-dir output/
先说一下各个参数的意思:
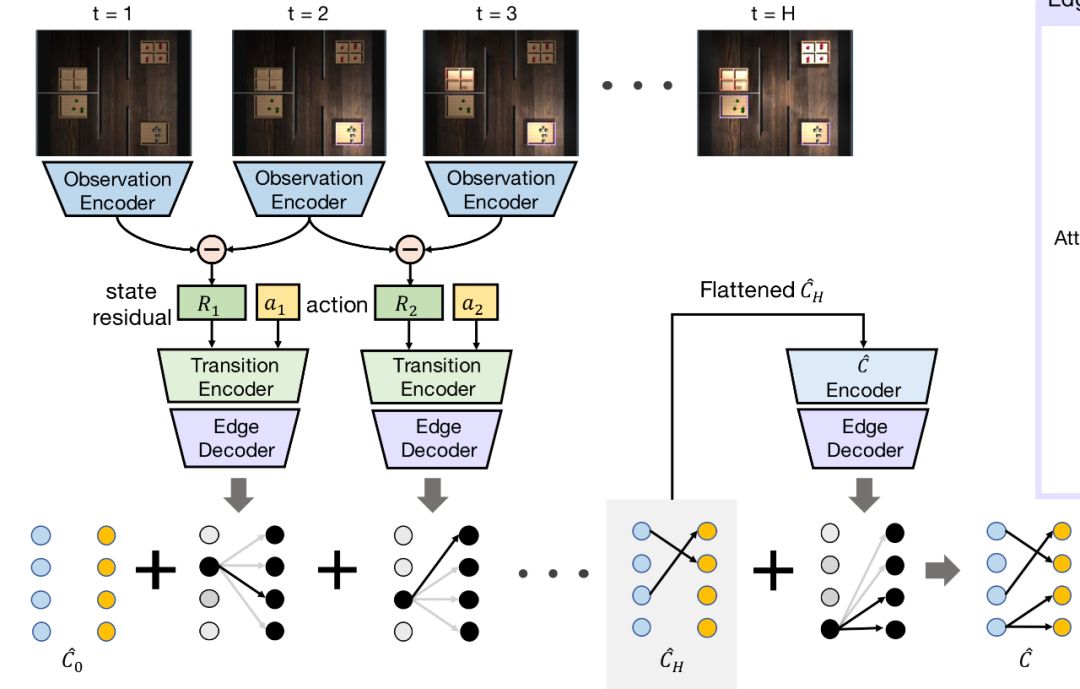
horizon是上图中H的值,num是开关或灯的数量,–fixed-goal是指学习是否是goal conditioned,即agent在采取行动的时候是只需要考虑现在的状态(state)还是也需要考虑目标(goal),在这个研究里,如果–fixed-goal=0,那表示有多个目标,是goal-conditioned。structure是开关和灯的结构关系,也是这个案例中的因果关系,有如下四类:
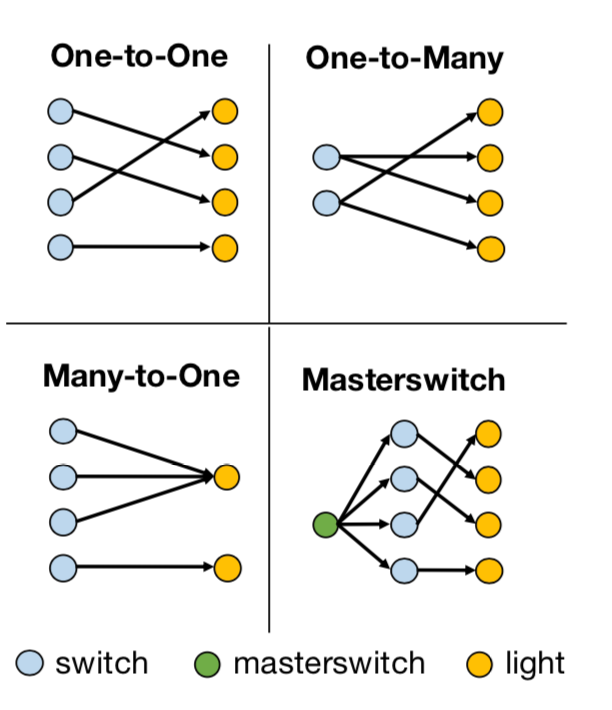
每一类都可以组合出非常多不同的因果关系,比如说One-to-One这种情况,有七组开关和灯,那么开关和灯之间可以有5040种不同的因果关系。在训练的过程中,给的训练数据会包含一些因果关系,最后需要测试训练好的agent在它从未见过的因果关系上的效果。seen这个参数是会参与训练的因果关系的数量,在这篇论文中,seen这个值会被设为10,50,100和500来做实验。images这个参数如果设定为1,表示会存储场景图片,而如果设为0,则不会存储观察到的场景图,而是灯的状态向量。data_dir,数据的存储路径。
1.1 初始化环境
l = LightEnv(args.horizon, args.num, st, args.structure, gc, filename=str(gc)+"_traj", seen = args.seen)
对照着环境的初始定义来看:
'''Light Switch Environment for Visual Causal Induction'''
def __init__(self, horizon=5, num=5, cond="gt", structure="one_to_one", gc=True, filename=None, seen=10):
horizon,num,structure,seen,延续上面的意义和取值,gc是goal conditioned的意思,gc=1-fixed_goal,filename是在程序过程中记录log的地方,st/cond这个参数在生成数据这块似乎是没有用到的。
初始化因果关系的二值矩阵:
self.aj = np.zeros((self.num, self.num))
初始化目标:
if self.gc:
self.goal = self._sample_goal()
def _sample_goal(self):
"""Samples a new goal and returns it.
"""
state = np.random.randint(0, 2, size=(self.num))
print(state)
light = np.dot(state.T, self.aj)
print(light)
light = light % 2
self.sim.model.light_active[:] = light
print(dir(self.sim))
self.goalim = self.sim.render(mode='offscreen', width=32, height=32, camera_name="birdview") / 255.0
return light
随机生成一组开关的状态,与因果关系相乘,得到灯的状态,再将灯的状态传给环境,渲染出目标场景图,返回灯的状态,这即是要达到的目标状态。
初始化开关的状态:
self.state = np.zeros((self.num))
排列组合出所有可能的因果关系:
if (self.structure == "one_to_many") or (self.structure == "many_to_one"):
if self.num == 9:
self.all_perms = self.generate_cs_set1(self.num, True)
else:
self.all_perms = self.generate_cs_set1(self.num)
else:
self.all_perms = self.generate_cs_set2(self.num)
np.random.shuffle(self.all_perms)
如果是one-to-one的结构,那么all_perms会包含所有可能的5040(7!)种因果关系,每种因果关系用一个N维向量表示,如[3, 4, 7, 0, 1, 2, 5, 6],表示开关0控制着灯3,…。如果是one-to-many或者many-to-one的结构,all_perms包含所有可能的823543(7^7)种因果关系。如果开关和灯的数量都是9,那么one-to-many或者many-to-one的因果关系会有9^9个,上亿了,因此需要随机过滤掉一些,除了最底层,每一层会随机过滤掉40%,最后大约会取到因果总数的0.6^8。值得注意的是,如果是many_to_one, 那么需要把向量的位置理解成开关,如果是one_to_many,则要把向量的位置理解成灯的编号,而里面的数字是开关的编号。得到all_perms后要将里面的因果关系随机排序。
获得当前的场景向量:
obs = self._get_obs()
obs向量中包含了灯的状态,目标向量,还有轨迹向量,目标向量和轨迹向量在生成数据的过程中没有被使用到。
定义动作域和观察域,这两个在生成数据的过程中也没有被用到。
self.action_space = spaces.Discrete(self.num+1)
self.observation_space = spaces.Box(0, 1, shape=obs.shape, dtype='float32')
1.2 获得训练样本
在这个实验中,会生成num_episodes组样本,样本存在buffer中,样本对应的因果关系,存在gtbuffer中。
buffer = []
gtbuffer = []
num_episodes = 40000
每组样本又如何生成?重设环境,重新选择因果关系,设定新的目标,获得新的初始状态的观察向量。
l.keep_struct = False
obs = env.reset()
l.keep_struct = True
if train:
ind = np.random.randint(0, self.seen)
else:
ind = np.random.randint(self.seen, self.pmsz)
perm = self.all_perms[ind]
## Set graph according to causal structure
if self.structure == "one_to_one":
aj = np.zeros((self.num,self.num))
for i in range(self.num):
aj[i, perm[i]] = 1
self.aj = aj
self.gt = self.aj.flatten()
elif self.structure == "one_to_many":
aj = np.zeros((self.num,self.num))
for i in range(self.num):
aj[i, perm[i]] = 1
self.aj = aj.T
self.gt = self.aj.flatten()
elif self.structure == "many_to_one":
aj = np.zeros((self.num,self.num))
for i in range(self.num):
aj[i, perm[i]] = 1
self.aj = aj
self.gt = self.aj.flatten()
elif self.structure == "masterswitch":
aj = np.zeros((self.num,self.num))
for i in range(self.num):
aj[i, perm[i]] = 1
self.aj = aj
self.ms = np.random.randint(self.num)
m = np.zeros((self.num))
m[self.ms] = 1
self.gt = self.aj.flatten()
self.gt = np.concatenate([self.gt, m])
如果是要获取训练样本,则在seen的范围内选择因果关系,否则在seen的范围外选择因果关系。选择到因果关系后,将一维向量转换成二维二值向量。若是masterswitch结构,还需要随机产生一个master switch。
生成样本的时候,当structure是masterswitch的时候,agent会先把所有的开关都试一遍,找出master switch,再将master之外的开关试一遍:
if args.structure == "masterswitch":
it = None
for i in range(args.num):
p = l._get_obs()
if args.images:
pi = l._get_obs(images=True)
p = p.reshape((1, -1))
a = np.zeros((1, args.num+1))
a[:,i] = 1
if args.images:
mem = np.concatenate([np.expand_dims(pi.flatten(), 0), a], 1)
else:
mem = np.concatenate([p[:,:args.num], a], 1)
if i == 0:
epbuf = mem
else:
epbuf = np.concatenate([epbuf, mem], 0)
l.step(i, count = False)
p2 = l._get_obs()
if (p != p2).any():
it = i
break
for i in range(args.num):
if i != it:
p = l._get_obs()
if args.images:
pi = l._get_obs(images=True)
p = p.reshape((1, -1))
a = np.zeros((1, args.num+1))
a[:,i] = 1
if args.images:
mem = np.concatenate([np.expand_dims(pi.flatten(), 0), a], 1)
else:
mem = np.concatenate([p[:,:args.num], a], 1)
epbuf = np.concatenate([epbuf, mem], 0)
l.step(i, count = False)
ln = epbuf.shape[0]
buf = np.zeros((2 * args.horizon - 1, epbuf.shape[1]))
buf[:ln] = epbuf
保存当前的场景图后,执行动作,然后切换到下个场景,如果在找master switch,判断现在这个switch是不是master,如果是的话,结束找master的过程,进入下一阶段。
def step(self, action):
'''Step in env.
Args:
action: which switch to toggle
'''
## If "Do Nothing" Action
if action == self.num:
pass
else:
if self.structure == "masterswitch":
## Only once masterswitch is activated can others be activated
if (action == self.ms) or (self.state[self.ms] == 1):
change = np.zeros(self.num)
change[action] = 1
self.state = np.abs(self.state - change)
else:
change = np.zeros(self.num)
change[action] = 1
self.state = np.abs(self.state - change)
obs = self._get_obs()
done = False
info = {'is_success': self._is_success(obs)}
self.correct.append((info["is_success"]))
reward = self.compute_reward(obs, info)
return obs, reward, done, info
step会判断是否成功触发了开关,触发开关后是否成功达到了目标,以及计算得失,不过是否成功达到目标和计算得失都不会在这个阶段被用到,不论达没达到目标,所有的开关都会被试一遍(masterswitch结构可能不止一遍)。
记:
这个生成训练样本的程序是有比较多问题的:
1. 费内存,40000组样本都存在buffer里,最后才写入文件,内存小的电脑不要轻易尝试。 2. 训练样本会用到的因果关系很少,实验中只会尝试10,50,100,500,而buffer中存入的数据,其实只和场景,因果关系,因果结构(structure),开关数量,可见的seen有关,步骤又都是顺序的,所以如果seen是10,则buffer中的40000组训练数据中只有10组不同的数据。在生成数据的程序中,每组数据的生成都重新对环境渲染,整个过程费时间,费内存,费计算,存下来废硬盘,重新读入还是费时费内存,可以优化,换一种写法和存训练数据的方法,会更合理。 3. 在初始化环境的时候,似乎不需要定义st/cond的值。
上篇:换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务(上)
参考论文:
- Suraj Nair, Yuke Zhu, Silvio Savarese, Li Fei-Fei, Stanford University, CAUSAL INDUCTION FROM VISUAL OBSERVATIONS FOR GOAL DIRECTED TASKS, 2019
参考代码:
- https://github.com/StanfordVL/causal_induction


Comments