
上篇:换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务——生成数据
上上篇:换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务(上)
今天我们来说一说《CAUSAL INDUCTION FROM VISUAL OBSERVATIONS FOR GOAL DIRECTED TASKS》实验中训练归纳模型的部分。
官方源代码地址:
https://github.com/StanfordVL/causal_induction
1. 归纳模型训练(Train Induction Model)
python3 trainF.py --horizon 7 --num 7 --fixed-goal 0 --structure one_to_one --type iter --images 1 --seen 10 --data-dir output/
先说一下各个参数的意思:
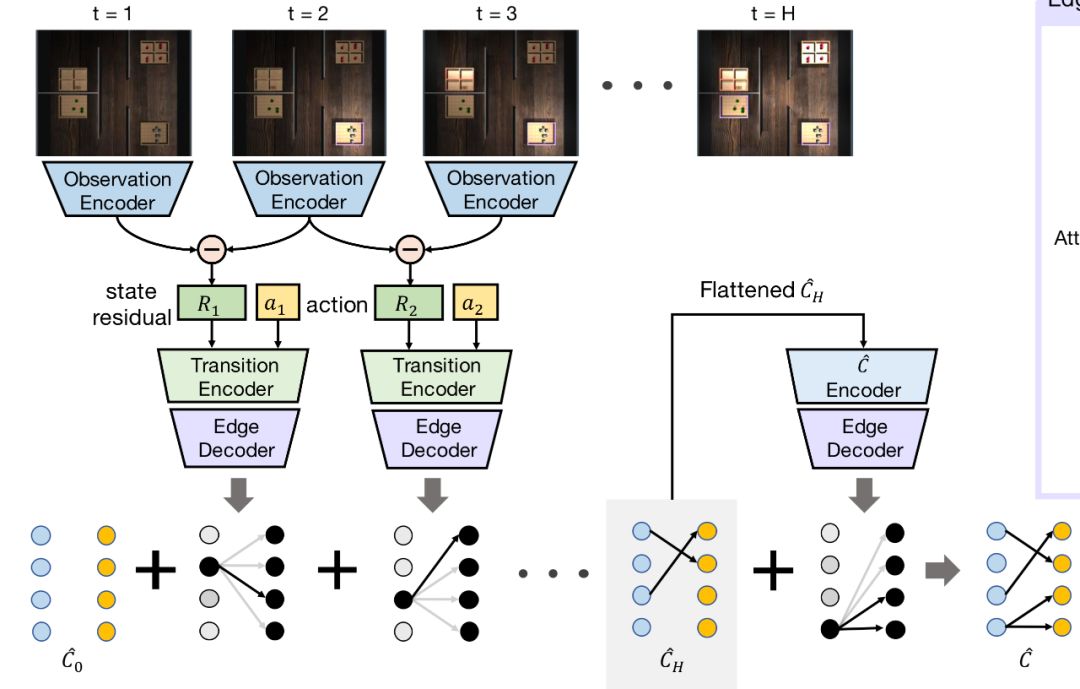
horizon是上图中H的值,num是开关或灯的数量,–fixed-goal是指学习是否是goal-conditioned,如果–fixed-goal=0,那表示有多个目标,是goal-conditioned。structure是开关和灯的控制模式,有如下四类:
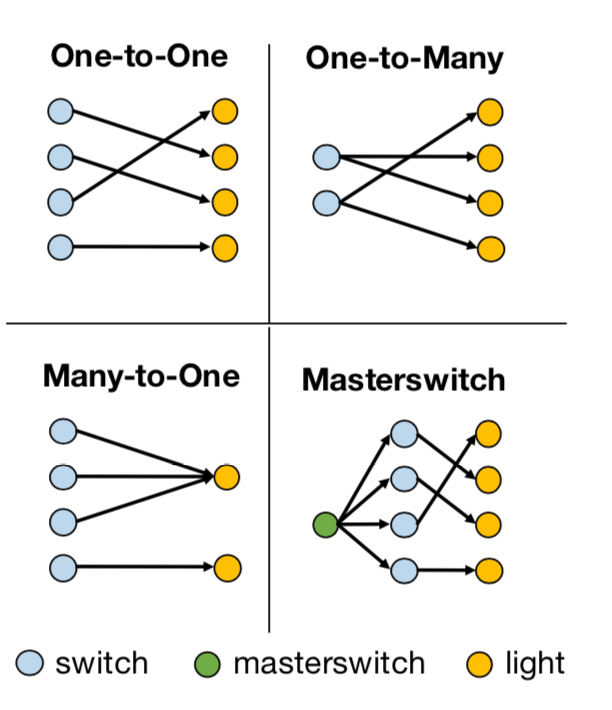
每一类都可以组合出非常多不同的因果关系,比如说One-to-One这种情况,如果有七组开关和灯,那么开关和灯之间可以有5040种不同的因果关系。在训练的过程中,给的训练数据会包含一些因果关系,最后需要测试训练好的agent在它从未见过的因果关系上的效果。seen这个参数用于设定参与因果归纳模型训练的因果关系的数量,在这篇论文中,seen这个值会被设为10,50,100和500来做实验。images这个参数如果设定为1,表示会存储场景图片,而如果设为0,则不会存储观察到的场景图,而是灯的状态向量。data_dir,数据的存储路径。
上面这些参数,上篇生成数据中都有出现,这篇多出的是type,用来指定模型,有三个模型可指定,分别是Iterative causal induction network (ICIN),temporal convolutions (TCIN),iterative model without the attention mechanism (ICIN (No Attn))。对应的参数分别是iter_attn,cnn,和iter。
1.1 初始化模型
F = IterativeModel(args.horizon, args.num, ms = msv, images=args.images)
对照着模型的定义来看:
def __init__(self, horizon,num=5, ms=False, images=False):
ms是指structure是否是masterswitch模式,当structure是masterswitch的时候,ms为True,horizon = 2args.horizon -1,不然,ms为False,horizon是args.horizon。原因上一篇有说过,找master switch的时候需要把所有switch遍历一遍,再将剩下的N-1个switch遍历一遍。
1.2 训练模型
train_supervised(F, a, a2, args.num, steps=2000, bs=512, images=args.images)
对照着函数定义来看:
def train_supervised(F, buf, gtbuf, num, steps = 1, bs=32, images=False):
F是定义的模型,buf是预存的训练样本,gtbuf是预存的训练样本对应的因果关系,steps是训练多少轮,bs是batch size的意思,是每轮有多少个样本参与训练。
前35000个样本做训练,后5000做测试。分别随机排序,提取前bs个样本做训练和测试。
perm = th.randperm(buf.size(0)-5000)
testperm = th.randperm(5000) + 35000
idx = perm[:bs]
samples = buf[idx]
gts= gtbuf[idx]
testidx = testperm[:bs]
testsamples = buf[testidx]
testgts= gtbuf[testidx]
从样本中分离出状态(states)和动作(actions):
states = samples[:, :, :split].contiguous().view(bs, -1).cuda()
actions = samples[:, :, split:].contiguous().view(bs, -1).cuda()
获得每组样本对应的因果关系(y),另外用样本预测出因果关系(y’):
groundtruth = gts.cuda()
pred = F(states, actions)
计算损失,调用反向传播函数调整网络:
loss = ((pred - groundtruth)**2).sum(1).mean()
testloss = ((testpred - testgroundtruth)**2).sum(1).mean()
loss.backward()
接下来看实验中三个模型:
1.3 ImageEncoder
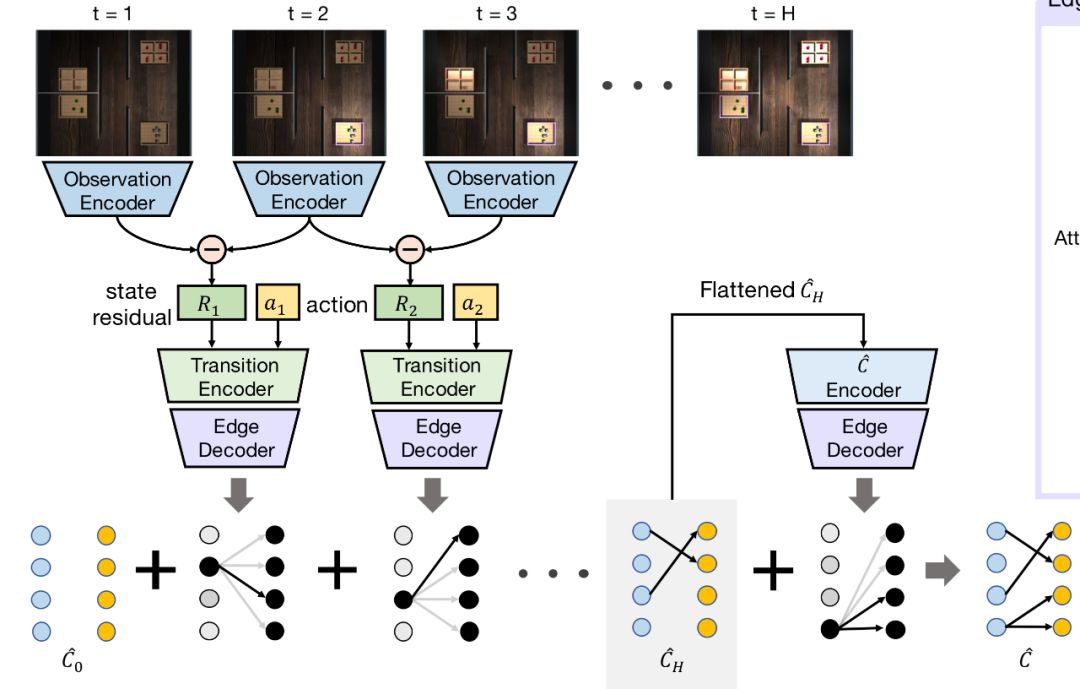
先说三个模型都会用到的ImageEncoder,对应的是图中的Observation Encoder,将32×32×3的图形输入这个ImageEncoder,输出是维度为N的向量,这里N是灯的数量,如果ImageEncoder被训练好了,这个向量理想状况应该要能表示灯的状态。所以ImageEncoder的作用是将图像转换为灯的状态向量。网络结构如下,具体可以参看源代码,三层卷积池化激励,最后一层全连接层。
e1 = self.encoder_conv(x) # 3*32*32 -> 8*16*16
e2 = self.encoder_conv2(e1) # 8*16*16 -> 16*8*8
e3 = self.encoder_conv3(e2) # 16*8*8 -> 32*4*4
e3 = e3.view(e3.size(0), -1) # 16*8*8 -> 32*4*4
encoding = self.fc(e3) # 32*4*4 -> N
1.4 ICIN (No Attn), TCIN 相同部分
三个模型的forward一开始都会经历这一段代码:
if self.images:
s_im = s.view(-1, 32, 32, 3).permute(0,3,1,2)
senc = self.ie(s_im)
sp = senc.view(-1, self.horizon, self.num)
else:
sp = s.view(-1, self.horizon, self.num)
sp[:,1:] = sp[:,1:] - sp[:,:-1] # TCIN 没有这行
a = a.view(-1, self.horizon, self.num+1)
e = th.cat([sp, a], 2)
s是states,是灯的状态图,将样本的维度格式转换成适合ImageEncoder处理的格式,转变成灯的状态向量,动作后的状态向量减去动作前的状态向量,得到状态差(对应的是上面结构图中的state residual),将状态差向量与动作向量拼接。之前生成样本的时候有说过,每组样本是agent采取了一系列动作之后,得到的一系列状态,那么后一个状态减去前一个状态,则是动作让环境产生的变化。要留意的是,TCIN中没有求状态差。
1.3 ICIN
初始化,下面不是所有的初始化代码,有些看了就能明白,不需要提到的,且三个模型都一样的初始化代码就没放上来。
if self.ms:
self.attnsize = num + 1
self.outsize = num
else:
self.attnsize = num
self.outsize = num
self.fc1 = nn.Linear(2*num+1, 1024)
self.fc3 = nn.Linear(512, self.attnsize + num)
self.fc4 = nn.Linear(self.attnsize*self.outsize, self.attnsize + num)
self.softmax = nn.Softmax(dim=1)
这里我们有可能会觉得古怪的是fc1的输入维度是2×N+1,照理来说,输入是动作向量和状态差向量,两个向量大小应该一致,都是N才对,拼起来是2×N才对,但却多了一维出来,原因是动作向量多了一维,动作向量是N+1维。这个设计到现在没有看出来有什么用,多出来的那维好像也没有被用到过。
p = th.zeros((sp.size(0), self.attnsize, self.outsize)).cuda()
for i in range(self.horizon):
inn = e[:,i,:]
e1 = self.relu(self.dp(self.fc1(inn))) # 2N+1 -> 1024
e2 = self.relu(self.dp(self.fc2(e1))) # 1024 -> 512
e3 = self.fc3(e2) # 512 -> attnsize+N
atn = self.softmax(e3[:, :self.attnsize]).unsqueeze(-1)
e3 = self.sigmoid(e3[:, self.attnsize:].unsqueeze(1).repeat(1, self.attnsize, 1))
r = atn * e3
p = p + r
这一段代码对应图中Transition Encoder和Edge Decoder两个部分,agent每做一个动作,就会对状态差进行一次编码解码。Transition Encoder 的部分是三层全连接层,对应的是代码中inn->e3的部分,最后输出的大小是attnsize+N的向量。而Edge Decoder的原理图如下:
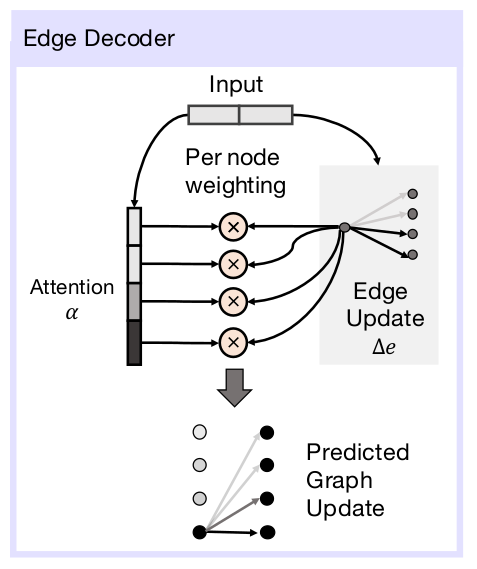
将Transition Encoder输出的向量分解为上图中Attention的部分和Edge Update的部分,两部分相乘,预测出最后的因果关系。Attention是N维,或者N+1维(当structure是masterswitch的时候),Edge Update是N维向量,所以最后p(Predicted Graph Update)的维度或大小是N×N或者(N+1)×N。
这部分的公式表达为:
<div align=center> </div>
</div>
<div align=center>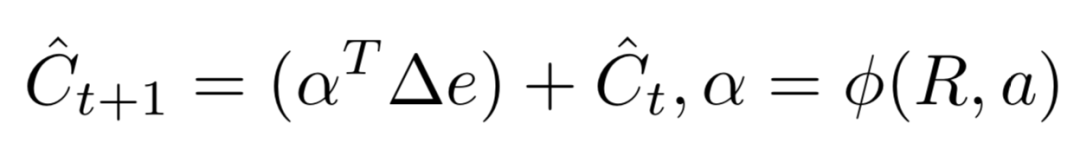 </div>
</div>
到这里,我们要回过头去看一个问题,上一小节中sp的维度是horizon×N,但这其实不是很合理,sp存储随动作序列产生的状态向量,加上最原始的状态,进行了horizon个动作的序列,应该会有horizon+1个状态,但是这个程序在最开始生成数据的时候,没有存储最后一个动作执行后的状态向量,因此sp是horizon×N维,而存储状态差的sp[:,1:]只有(horizon-1)×N维,那和最后一个动作拼接的其实是最后一个动作执行前的状态向量,而不是这个动作造成的状态差向量,这样最后一个输入和其他输入在意义上完全不一样,这样的设计感觉是逻辑上的疏失,也可能会对训练出来的模型精确度造成不小的影响。
结构图上也能体现这个疏失,下面产生的因果关系是从1到H,但照图上的逻辑,状态差只能从1到H-1。
最后,再多一个编码解码的过程,得到最后的因果关系。不是很理解,为什么最后加这么一段网络。根据论文上的描述,应该是如果最后还有灯没有和哪个开关产生因果关系,由这一段来补齐,这样有点像在补前两段提到的训练代码设计的不合理的地方。
e3 = self.fc4(p.view(-1, self.attnsize*self.num)) # attnsize*N -> attnsize+N
atn = self.softmax(e3[:, :self.attnsize]).unsqueeze(-1)
e3 = self.sigmoid(e3[:, self.attnsize:].unsqueeze(1).repeat(1, self.attnsize, 1))
r = atn * e3
p = p + r
p = p.view(-1, self.attnsize*self.num)
至于Attention机制的设计,可以这样想,因果关系里Edge Update决定哪些列是有效的,Attention决定哪些行是有效的。在因果关系矩阵里,列坐标表示的是开关编号,行坐标表示的是功能,即控制哪个灯,是否是master switch。理论上,如果网络训练的足够好,Attention会指示这一步哪些功能被开关触发,Edge Update会指示触发了哪些开关。
1.4 ICIN (No Attn)
初始化部分,没有Attention的机制,输出的outsize即因果关系向量的大小:
if self.ms:
self.outsize = num**2 + num
else:
self.outsize = num**2
self.fc1 = nn.Linear(2*num+1, 1024)
self.fc3 = nn.Linear(512, self.outsize)
self.fc4 = nn.Linear(self.outsize, self.outsize)
forward部分,:
e = e.permute(0,2,1)
c2 = e
p = th.zeros((sp.size(0), self.outsize)).cuda()
for i in range(self.horizon):
e1 = self.relu(self.dp(self.fc1(c2[:,:,i]))) # 2N+1 -> 1024
e2 = self.relu(self.dp(self.fc2(e1))) # 1024 -> 512
e3 = self.sigmoid(self.fc3(e2)) # 512 -> attnsize+N
p = p + e3
p = self.sigmoid(self.fc4(p))
因为没有了Attention机制,自然也没有了Encoder,Decoder的区分,在时序中,三层全连接网络将灯的状态差和动作向量转换成因果关系,最后再通过一层全连接网络得到最后的因果关系。
1.5 TCIN
初始化部分,和前两个网络不同的地方是,除了有全连接层,还有三个卷积层:
if self.ms:
self.outsize = num**2 + num
else:
self.outsize = num**2
self.cnn1 = nn.Conv1d(2*num+1, 256, kernel_size=3, padding=1)
self.cnn2 = nn.Conv1d(256, 128, kernel_size=3, padding=1)
self.cnn3 = nn.Conv1d(128, 128, kernel_size=3, padding=1)
self.fc1 = nn.Linear(self.horizon*128, 1024)
self.fc3 = nn.Linear(512, self.outsize)
forward部分:
e = e.permute(0,2,1)
c1 = self.relu(self.cnn1(e)) # (2N+1)*horizon -> 256*horizon
c2 = self.relu(self.cnn2(c1)) # 256*horizon -> 128*horizon
c2 = self.relu(self.cnn3(c2)) # 128*horizon -> 128*horizon
c2 = c2.view(-1, self.horizon*128)
e1 = self.relu(self.dp(self.fc1(c2))) # 128*horizon -> 1024
e2 = self.relu(self.dp(self.fc2(e1))) # 1024 -> 512
rec = self.sigmoid(self.fc3(e2)) # 512 -> (N+1)N
return rec
先将状态向量组合在一起,然后经过三层一维卷积层,再经过三层全连接层,输出最后因果向量。
卷积网络设计的过分简单了。
2. 因果模型评估(Causal Model Evaluation)
这部分内容不多,就和训练写在一块了。
python3 evalF.py --horizon 7 --num 7 --fixed-goal 0 --structure one_to_one --method trajFi --images 1 --seen 10 --data-dir output/
method对应的是模型的种类,指定为trajF,为TCIN,指定为trajFia,为ICIN,其他为ICIN (No Attn),这里选择ICIN评估。
初始化环境,tj = “gt”时,l.gt是一维化后的因果关系向量,filename用于记录l.step运行过程中产生的log,在这篇中,没有被调用:
gc = 1 - args.fixed_goal
tj = "gt"
l = LightEnv(args.horizon, args.num, tj, args.structure, gc, filename="exp/"+str(gc)+"_"+args.method, seen = args.seen)
env = DummyVecEnv(1 * [lambda: l])
加载模型:
F = th.load(args.data_dir+"iter_attn_Redo_L2_S"+str(args.seen)+"_h"+str(args.horizon)+"_"+str(args.structure)+addonn).cuda()
F = F.eval() # 模型中有用到dropout或者BN,需要设定eval模式进行测试,ta
模型中有用到dropout或者BN,需要设定eval模式进行测试,train模式进行训练。
测试过程,先重置环境,用训练过程中用到的因果关系生成一组数据,用模型生成预测的因果关系,和真正的因果关系对比,求F1 Score,再将环境设置为test模式,重置环境,用训练没有用过的因果关系生成一组数据,用模型预测因果关系,和真正的因果关系对比,求F1 Score。如此循环一百次,分别计算训练中用过的因果关系产生的F1 Scores和没用过的因果关系产生的F1 Scores的均值。
代码如下:
for mep in range(100):
l.keep_struct = False
obs = env.reset() #重置环境,主要作用是切换因果关系
l.keep_struct = True
buf = induction(args.structure,args.num, args.horizon, l, images=args.images)
pred = predict(buf, F,args.structure, args.num)
f = f1score(pred, l.gt)
trloss.append(f)
#### TEST ON UNSEEN CS
l.keep_struct = False
l.train = False #将train设置为False,则因果关系会从训练样本中没有出现果的集合中选择
obs= env.reset()
buf = induction(args.structure,args.num, args.horizon, l, images=args.images)
pred = predict(buf, F,args.structure, args.num)
f = f1score(pred, l.gt)
tsloss.append(f)
l.keep_struct = True
l.train = True
print(np.mean(trloss), np.mean(tsloss))
induction的部分和生成数据中产生样本的部分完全一致,就不贴出来说了,输出是生成测试要用的样本图序列,以及对应的动作。
predict函数,predgt是模型根据分解出的状态图组和动作组得到的因果关系:
s = th.FloatTensor(buf[:,:-(num+1)]).float().cuda()
a = th.FloatTensor(buf[:,-(1+num):]).float().cuda()
predgt = F(s, a)
最后F1 Score函数,gt是这个环境现在真实使用的因果关系:
p = 1 * (pred > 0.5) # 结果二值化,0 or 1
if np.sum(p) == 0:
prec = 0
else:
prec = np.sum(gt * p) / np.sum(p)
rec =np.sum(gt*p) / np.sum(gt)
if (prec == 0) and (rec==0):
return 0
return 2 * (prec * rec) / (prec+rec)
论文里尝试调整了switch的数量,在四种structure模式下测试了三种模型的效果,ICIN的方法要优于其他两种方法很多,且受switch数量影响较小。

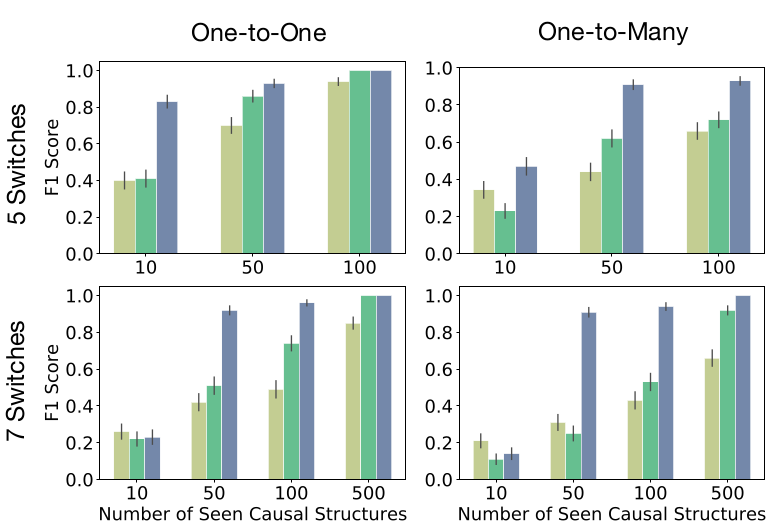
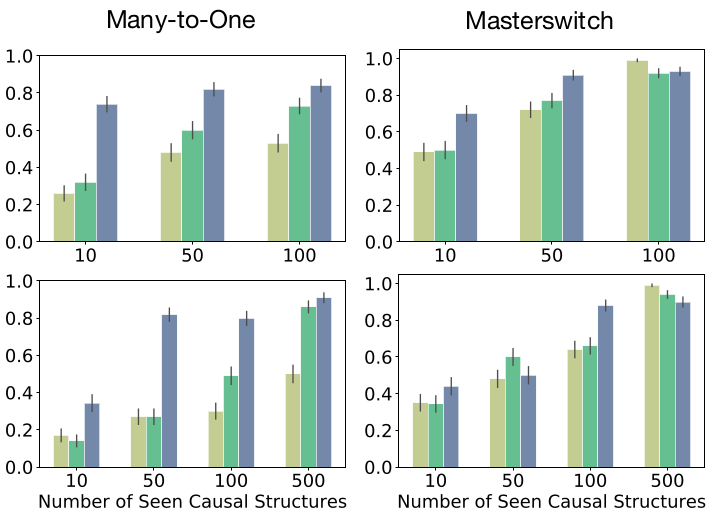
这篇论文的代码解析还有一篇,是策略模型的定义,训练和评估。敬请关注和期待。(PS: 看代码看得有点想吐了,缓缓,先更一集因果课再回头把最后一部分代码更完)
记:
这个训练模型的程序也是有比较多问题的:
1. 训练过程中的testloss应该用模型没见过的因果关系更合适,不然出来的数据,几乎和loss一样,并没有很大参考价值。 2. action,动作向量设置成了N+1维,似乎没有必要。 3. 每组样本序列,生成的最后一张图没有保存下来,保存的是最开始的,和最后一个动作执行前的图,程序里和最后一个动作拼接的其实是最后一个动作执行前的状态向量,而不是这个动作造成的状态差向量,这样最后一个输入和其他输入意义上非常不一样,这样的设计感觉是逻辑上的疏失。 4. 因果归纳网络的结构图有容易让人误解的地方。 5. evalF中定义的st没有用到
上篇:换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务——生成数据
上上篇:换个思路实现人工智能: 在视觉环境中用因果归纳完成目标导向的任务(上)
参考论文:
- Suraj Nair, Yuke Zhu, Silvio Savarese, Li Fei-Fei, Stanford University, CAUSAL INDUCTION FROM VISUAL OBSERVATIONS FOR GOAL DIRECTED TASKS, 2019
参考代码:
- https://github.com/StanfordVL/causal_induction


Comments