
之前有讲过一篇论文,今天来讲讲它的代码:
/1.png)
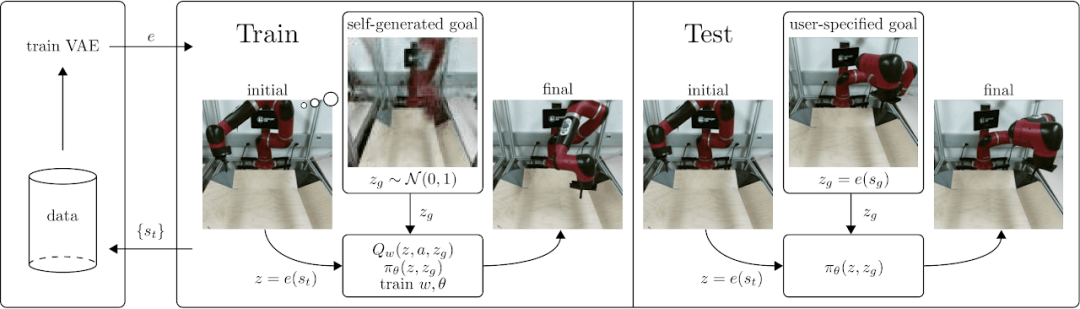
论文解析的链接是:以图片为目标的视觉强化学习
/2.png)
这篇研究以及这篇研究的后续研究,源代码都有公开,我们的目标是把这个库都解析一遍,感兴趣的话,关注吧。下面是相关源代码的链接:
https://github.com/rail-berkeley/rlkit
现在要说的这个工作我们称呼它RIG,RIG适用的rlkit版本和最新的两个工作适用的rlkit版本不一样,我们先看RIG适用的rlkit。
论文开发者直接开发了一个工具,里面有众多强化学习的算法,方便做相关研究的渣渣们,比如我,直接拿来用,但前提你得看得懂/3.png) 。那么看懂就交给我了。
。那么看懂就交给我了。
我们先来安装和解析一下这个工具,首先看安装指引:
cp rlkit/launchers/config_template.py rlkit/launchers/config.py
然后我们看看config.py里面都做了些什么:
import os
from os.path import join
import rlkit
# 设定项目目录
rlkit_project_dir = join(os.path.dirname(rlkit.__file__), os.pardir)
LOCAL_LOG_DIR = join(rlkit_project_dir, 'data')
# 接下来设定大部分与远程服务器相关
# 代码目录,可能不止一个,不止一个就添加在后面
CODE_DIRS_TO_MOUNT = [
rlkit_project_dir,
# '/home/user/python/module/one', Add more paths as needed
]
# 工作需要用到mujoco模拟器,如果你mujoco安装的位置特殊,这里可能要改
DIR_AND_MOUNT_POINT_MAPPINGS = [
dict(
local_dir=join(os.getenv('HOME'), '.mujoco/'),
mount_point='/root/.mujoco',
),
]
# 跑程序的代码地址
RUN_DOODAD_EXPERIMENT_SCRIPT_PATH = (
join(rlkit_project_dir, 'scripts', 'run_experiment_from_doodad.py')
# '/home/user/path/to/rlkit/scripts/run_experiment_from_doodad.py'
)
# 接下来是AWS,SLURM,和GCP的一些设定,
# 我目前都没用到,暂时不提,用到的小伙伴可以看一下
关于config.py文件,不用doodad的话,要把下面两行改一下,不然之后跑程序会报错:
# If not set, default will be chosen by doodad
#AWS_S3_PATH = 's3://bucket/directory
改为(其实就是把注释去掉,再补个冒号),我的环境里它不会被用到,只是调试起来方便一些:
# If not set, default will be chosen by doodad
AWS_S3_PATH = 's3://bucket/directory'
接下来创建一个虚拟代码环境,他提供了三个虚拟环境配置文件:linux-cpu-env.yml,linux-gpu-env.yml,mac-env.yml。一般是linux-gpu:
conda env create -f environment/linux-gpu-env.yml
在跑之前我们看里面写了点啥,name是虚拟环境的名称,channels是虚拟环境安装软件的源,下面的dependencies是虚拟环境依赖的软件,这里就不列全了:
name: rlkit
channels:
- kne # for pybox2d
- pytorch
- anaconda # for mkl
dependencies:
- cython
- ipython # technically unnecessary
我自己不习惯用别人写好的脚本建立环境,喜欢一边看代码一边解决依赖问题。
首先我们要解决最重要的一个依赖,MuJoCo,强化学习的环境模拟常用的软件,以前是个付费软件,现在免费了,可能是有大佬买了,现在似乎属于DeepMind,DeepMind属于Google:
https://mujoco.org/
代码里用的MuJoCo版本是1.5,我喜欢用最新的,我们试试2.1,不行再回来换1.5,MuJoCo安装起来还是挺费劲的,遇到问题耐心些,多搜一搜:
mkdir -p ~/.mujoco
cd ~/.mujoco
# 到mujoco官网->download页面->选2.1.0版本->下载linux版
wget https://github.com/deepmind/mujoco/releases/download/2.1.0/mujoco210-linux-x86_64.tar.gz
tar -xvf mujoco210-linux-x86_64.tar.gz
echo 'export LD_LIBRARY_PATH=$HOME/.mujoco/mujoco210/bin:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
# 以上mujoco就下载安置好了
# 接下来安装mujoco-py
git clone https://github.com/openai/mujoco-py.git
cd mujoco-py
pip3 install -r requirements.txt
pip3 install -r requirements.dev.txt
python3 setup.py install
#----------------------------------------
# 接下来是一些你可能import mujoco_py失败,甚至上面就没装成功,而需要进行的步骤
# 按错误提示选择性执行
sudo apt-get install gcc
sudo apt install libosmesa6-dev
sudo apt-get install python3-devel
sudo apt-get update -y
sudo apt-get install -y patchelf
sudo apt-get install libglew-dev
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HOME/.local/bin' >> ~/.bashrc
echo 'export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libGLEW.so' >> ~/.bashrc
source ~/.bashrc
如果可以import mujoco_py执行成功,且可以跑一些示例代码,就表示安装成功了。
再回过头看rlkit,他除了提供虚拟环境的方案,还提供了Docker文件,Docker我不喜欢用,当然,主要是因为没下功夫,用不好,所以只能不喜欢,对这些比较擅长的可以试着用Docker。
rlkit调用GPU的方式:
import rlkit.torch.pytorch_util as ptu
ptu.set_gpu_mode(True)
如果用doodad来执行方法,则直接用下面的方式调用gpu,然而我测试发现,不用doodad,下面这种方式也可以成功调用gpu:
run_experiment(..., use_gpu=True)
他们会建议用doodad来执行python程序,这里我们更想偏向于原理性代码的讨论,doodad部分的代码就不涉及了。
接下来我们看RIG的代码,在examples/rig/目录下,有两个目录,四个文件,我们一个一个开始,首先看examples/rig/pointmass/rig.py:
from multiworld.envs.pygame.point2d import Point2DWallEnv
from rlkit.launchers.launcher_util import run_experiment
from rlkit.launchers.rig_experiments import grill_her_td3_full_experiment
要安装一下multiworld,这个工具也是该团队开发的:
git clone https://github.com/vitchyr/multiworld.git
cd multiworld
python setup.py install
pip install gym
pip install pygame
pip install boto3
pip install gtimer
pip install sk-video
pip install gitpython
关于安装rlkit,rlkit依赖版本较低的python和tensorflow,再加上跑不同程序要用到的rlkit版本还不太一样,我们反正要解析源代码,这里就不安装rlkit了,直接把rlkit的源码包放在主程序的目录下。如果想安装rlkit,可以按照他们给的方法操作,之后直接pip install rlkit就行。亲测不安装是可以的。
接着看main函数,先定义了一个字典,里面都是参数,字典里还嵌套字典,层层叠叠,难怪AI工程师会被调侃调参大师,这里暂时不一一看,之后用到了会提:
variant = dict(
imsize=84,
.......
algorithm='RIG',
)
配置完参数之后,就是跑训练代码了:
run_experiment(
grill_her_td3_full_experiment, #rig算法实验的函数,以variant为参数
exp_prefix='rlkit-pointmass-rig-example', #实验名称
# 实验方式:默认是local,我们这里没装doodad。
# 单机用here_no_doodad可以跑,也可以调用GPU
# 其他方式暂时不研究了,有兴趣的可以研究
# “local”,
# “docker_local”,
# “ec2”,
# 'here_no_doodad',
mode='here_no_doodad',
variant=variant, # 参数
use_gpu=True, # 要用GPU跑就打开
)
在这样的配置下,我们看代码是怎么跑的(会略过不太重要的代码),下面是run_experiment里比较重要的代码:
run_experiment_kwargs = dict(
# 实验名称,默认会带上时间
exp_prefix=exp_prefix,
# 参数
variant=variant,
# 实验ID
exp_id=exp_id,
# 随机种子,不设定就随机产生
seed=seed,
use_gpu=use_gpu,
# 默认是‘last’,作用之后说
snapshot_mode=snapshot_mode,
# 默认是1,作用之后说
snapshot_gap=snapshot_gap,
# 没装git就是None,暂时就None吧
git_infos=git_infos,
#这里应该是rig.py
script_name=main.__file__,
)
if mode == 'here_no_doodad':
run_experiment_kwargs['base_log_dir'] = base_log_dir
return run_experiment_here(
method_call,
**run_experiment_kwargs
)
接下来是run_experiment_here函数,依然是只看重要一点的代码:
# 这个函数里只有一行代码:
# logger.reset()
# logger也是他们自己开发的,reset就是回归初始状态
reset_execution_environment()
# 这里做的事情包括:创建log目录,将variant参数记录下来,
# 以及添加各式各样的路径和参数
actual_log_dir = setup_logger(
exp_prefix=exp_prefix,
variant=variant,
exp_id=exp_id,
seed=seed,
snapshot_mode=snapshot_mode,
snapshot_gap=snapshot_gap,
base_log_dir=base_log_dir,
log_dir=log_dir,
git_infos=git_infos,
script_name=script_name,
**setup_logger_kwargs
)
# 启用seed
set_seed(seed)
# 启用GPU,默认用id为0的GPU
# 如果想选择用其他gpu,可以set_gpu_mode(use_gpu,gpu_id)
set_gpu_mode(use_gpu)
run_experiment_here_kwargs = dict(
variant=variant,
exp_id=exp_id,
seed=seed,
use_gpu=use_gpu,
exp_prefix=exp_prefix,
snapshot_mode=snapshot_mode,
snapshot_gap=snapshot_gap,
git_infos=git_infos,
script_name=script_name,
base_log_dir=base_log_dir,
**setup_logger_kwargs
)
# 把参数信息存成actual_log_dir下面的experiment.pkl文件
save_experiment_data(
dict(
run_experiment_here_kwargs=run_experiment_here_kwargs
),
actual_log_dir
)
# 好了,终于到我们的算法函数了。
# 其实是这样的 grill_her_td3_full_experiment(variant)
return experiment_function(variant)
接下来到这里:
def grill_her_td3_full_experiment(variant):
# 看名字就知道功能了,预处理
full_experiment_variant_preprocess(variant)
# 训练vae,一边训练还会一边自己调参哦
train_vae_and_update_variant(variant)
# 这个看了再说。
grill_her_td3_experiment(variant['grill_variant'])
这篇先到这里吧,我累了/4.png) 。下篇会讲具体模型算法还有训练测试代码,希望一个下篇就解决,不需要再分个中下
。下篇会讲具体模型算法还有训练测试代码,希望一个下篇就解决,不需要再分个中下/5.png) 。
。
感兴趣的小伙伴们就关注吧。觉得有用右下角帮忙点个赞哦。
Comments